Las Physics-Informed Neural Networks (PINNs) son un enfoque innovador que combina redes neuronales con ecuaciones diferenciales gobernantes para resolver problemas complejos de física (Blechschmidt y Ernst 2021). A diferencia de métodos tradicionales, las PINNs incorporan directamente las ecuaciones físicas en su función de pérdida mediante diferenciación automática, lo que permite minimizar simultáneamente el error en los datos y el residual de las PDEs (George Em Karniadakis 2021). Esta característica las hace particularmente valiosas en escenarios con datos limitados, donde el conocimiento físico actúa como un regularizador efectivo. La capacidad de aproximación de las PINNs se fundamenta en el teorema de aproximación universal de las redes neuronales, adaptado para incorporar restricciones físicas a través de términos de penalización en la función de optimización (George Em Karniadakis 2021).
como ejemplo, se considera la ecuación de Burgers para viscocidad:
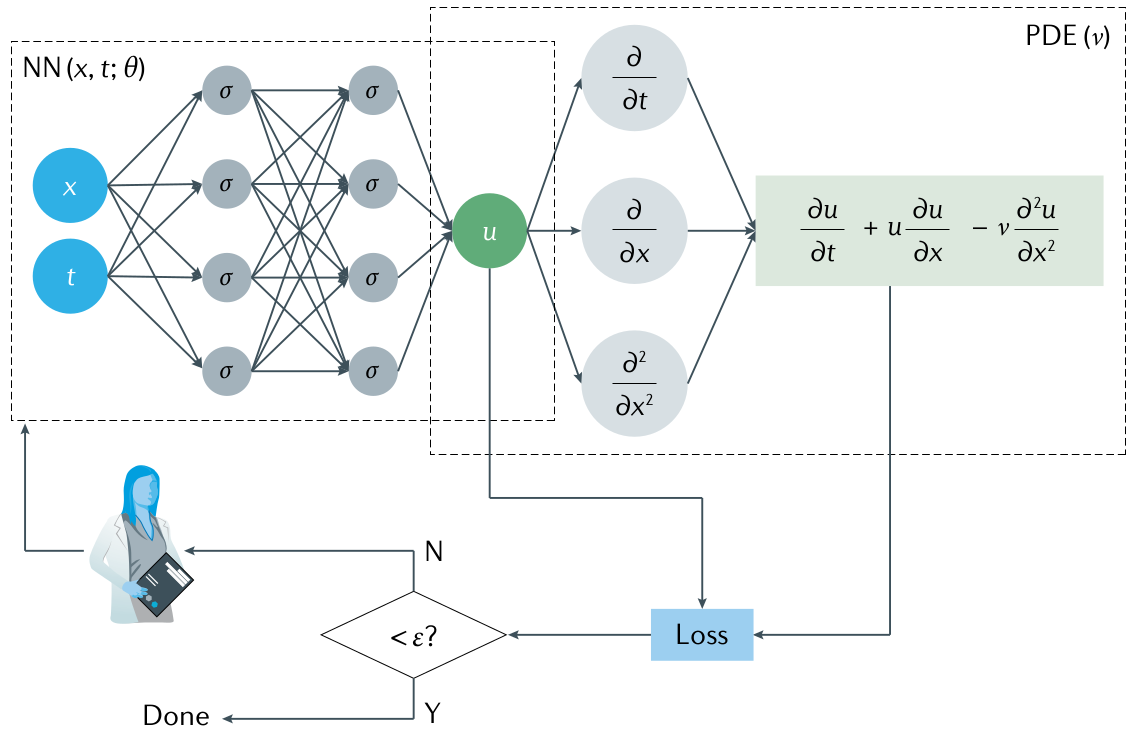
con una condición inicial adecuada y condiciones de contorno de Dirichlet. En la Figura 7.1, la red izquierda (physics-uninformed) representa el sustituto de la solución de EDP \(u(x, t)\), mientras que la red derecha (physics-informed) describe el residuo de EDP \(\frac{\partial u}{\partial t} + u \frac{\partial u}{\partial x} - \nu \frac{\partial^2 u}{\partial x^2} = 0\). La función de pérdida incluye una pérdida supervisada de las mediciones de datos de \(u\) de las condiciones iniciales y de contorno, y una pérdida no supervisada de EDP:
Aquí, \((x_i, t_i)\) representan puntos donde se conocen valores de la solución y \((x_j, t_j)\) son puntos interiores del dominio. Los pesos \(w_{\text{data}}\) y \(w_{\text{PDE}}\) equilibran la contribución de cada término. La red se entrena minimizando \(\mathcal{L}\) usando optimizadores como Adam o L-BFGS hasta alcanzar un umbral \(\varepsilon\)(George Em Karniadakis 2021).
Este enfoque permite resolver EDPs (clásicas, fraccionarias o estocásticas) sin mallas, en dominios complejos o con datos escasos y ruidosos, siendo una herramienta flexible y poderosa para la modelación científica.
Figura 7.1: El algoritmo de una PINN. Se construye una red neuronal (NN) \(u(x, t; \theta)\) donde \(\theta\) representa el conjunto de pesos entrenables \(w\) y sesgos \(b\), y \(\sigma\) representa una función de activación no lineal. Especifique los datos de medición \({x_i, t_i, u_i}\) para \(u\) y los puntos residuales \({x_j, t_j}\) para la EDP. Se especifica la pérdida \(\mathcal{L}\) en la Ecuación 7.1 sumando las pérdidas ponderadas de los datos y la EDP. Entrene la NN para encontrar los mejores parámetros \(\mathbb{\theta^*}\) minimizando la pérdida \(\mathcal{L}\)(George Em Karniadakis 2021).
7.1 Algoritmos de optimización
Un algoritmo de optimización busca minimizar o maximizar una función objetivo ajustando sus parámetros de manera iterativa. Son esenciales en el entrenamiento de redes neuronales y otros modelos de aprendizaje automático (Kingma y Ba 2014).
7.1.1 ADAM
Adaptive Moment Estimation (ADAM) combina estimaciones de primer y segundo momento del gradiente para adaptar las tasas de aprendizaje por parámetro. Utiliza promedios móviles exponenciales de gradientes y gradientes al cuadrado, corregidos por bias, lo que lo hace eficiente en problemas con gradientes ruidosos o dispersos. Es robusto y requiere poco ajuste hiperparamétrico (Kingma y Ba 2014).
7.1.2 L-BFGS
Limited-memory BFGS (L-BFGS) es un método quasi-Newton que aproxima la inversa del Hessiano usando un historial limitado de gradientes y actualizaciones de parámetros. Evita el costo computacional de almacenar matrices completas, lo que lo hace viable para problemas de alta dimensionalidad. Es especialmente útil en optimización batch o con gradientes estables (Goldfarb, Ren, y Bahamou 2016).
7.2 Deepxde
DeepXDE es una biblioteca en Python de aprendizaje profundo diseñada para resolver ecuaciones diferenciales, incluyendo ecuaciones diferenciales parciales (PDEs), ecuaciones integro-diferenciales (IDEs) y ecuaciones diferenciales estocásticas (SDEs), utilizando redes neuronales informadas por la física (PINNs). Combina técnicas de aprendizaje automático con principios físicos al incorporar las ecuaciones diferenciales directamente en la función de pérdida de la red neuronal, aprovechando la diferenciación automática para calcular derivadas de manera precisa y eficiente (Lu et al. 2021).
7.3 Ejemplo de resolución de la ecuación de Burger 1D con deepxde
con la condición de frontera de Dirichlet y condición inicial: \[
u(-1,t) = u(1,t) = 0, \quad u(x,0)=-\sin(\pi x).
\]
Código
import deepxde as ddeimport numpy as np# Definir una función para cargar los datosdef gen_testdata(): data = np.load("data/Burgers.npz") t, x, exact = data["t"], data["x"], data["usol"].T xx, tt = np.meshgrid(x, t) X = np.vstack((np.ravel(xx), np.ravel(tt))).T y = exact.flatten()[:, None]return X, y# Definir la PDEdef pde(x, y): dy_x = dde.grad.jacobian(y, x, i=0, j=0) dy_t = dde.grad.jacobian(y, x, i=0, j=1) dy_xx = dde.grad.hessian(y, x, i=0, j=0)return dy_t + y * dy_x -0.01/ np.pi * dy_xx# Definir los dominios espacial, temporal y juntarlosgeom = dde.geometry.Interval(-1, 1)timedomain = dde.geometry.TimeDomain(0, 0.99)geomtime = dde.geometry.GeometryXTime(geom, timedomain)# Definir la condición de fronterabc = dde.icbc.DirichletBC( geomtime,lambda x: 0,lambda _, on_boundary: on_boundary)# Definir la condición inicialic = dde.icbc.IC( geomtime,lambda x: -np.sin(np.pi * x[:, 0:1]),lambda _, on_initial: on_initial)# Definir la cantidad de puntos en el dominiodata = dde.data.TimePDE( geomtime, pde, [bc, ic], num_domain=2540, num_boundary=80, num_initial=160, num_test=300)# Definir la arquitectura de la red, así como# su función de activación y el inicializadornet = dde.nn.FNN([2] + [20] *3+ [1], "tanh", "Glorot normal")model = dde.Model(data, net)# Compilar el modelo y entrenarlomodel.compile("adam", lr=1e-3)losshistory, train_state = model.train(iterations=3000)model.compile("L-BFGS")losshistory, train_state = model.train()#dde.saveplot(losshistory, train_state, issave=False, isplot=True)
Código
import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3DX, y_true = gen_testdata()y_pred = model.predict(X)f = model.predict(X, operator=pde)# Extraer componentes de Xx_coords = X[:, 0] # coordenadas x (espacio)time = X[:, 1] # coordenadas t (tiempo)# Crear figura con dos subgráficos 3Dfig = plt.figure(figsize=(14, 8), constrained_layout=True)ax1 = fig.add_subplot(121, projection='3d')ax2 = fig.add_subplot(122, projection='3d')# Calcular límites comunes para los ejes zz_min =min(y_true.min(), y_pred.min())z_max =max(y_true.max(), y_pred.max())# Gráfico 1: Valores realessc1 = ax1.scatter(x_coords, time, y_true, c=y_true, cmap='viridis', marker='o', vmin=z_min, vmax=z_max)ax1.set_xlabel('Posición (x)')ax1.set_ylabel('Tiempo (t)')ax1.set_zlabel('u(x,t)')ax1.set_title('Valores reales de u(x,t)')ax1.set_zlim([z_min, z_max])ax1.set_box_aspect(None, zoom=0.9)# Gráfico 2: Valores predichossc2 = ax2.scatter(x_coords, time, y_pred, c=y_pred, cmap='viridis', marker='^', vmin=z_min, vmax=z_max)ax2.set_xlabel('Posición (x)')ax2.set_ylabel('Tiempo (t)')ax2.set_zlabel('u(x,t)')ax2.set_title('Valores predichos de u(x,t)')ax2.set_zlim([z_min, z_max])ax2.set_box_aspect(None, zoom=0.75)cbar = fig.colorbar(sc1, ax=(ax1,ax2), shrink=0.9, aspect=90, pad=0.1, orientation='horizontal')cbar.set_label('Magnitud de u(x,t)')plt.show()print("Error relativo L2:", dde.metrics.l2_relative_error(y_true, y_pred))
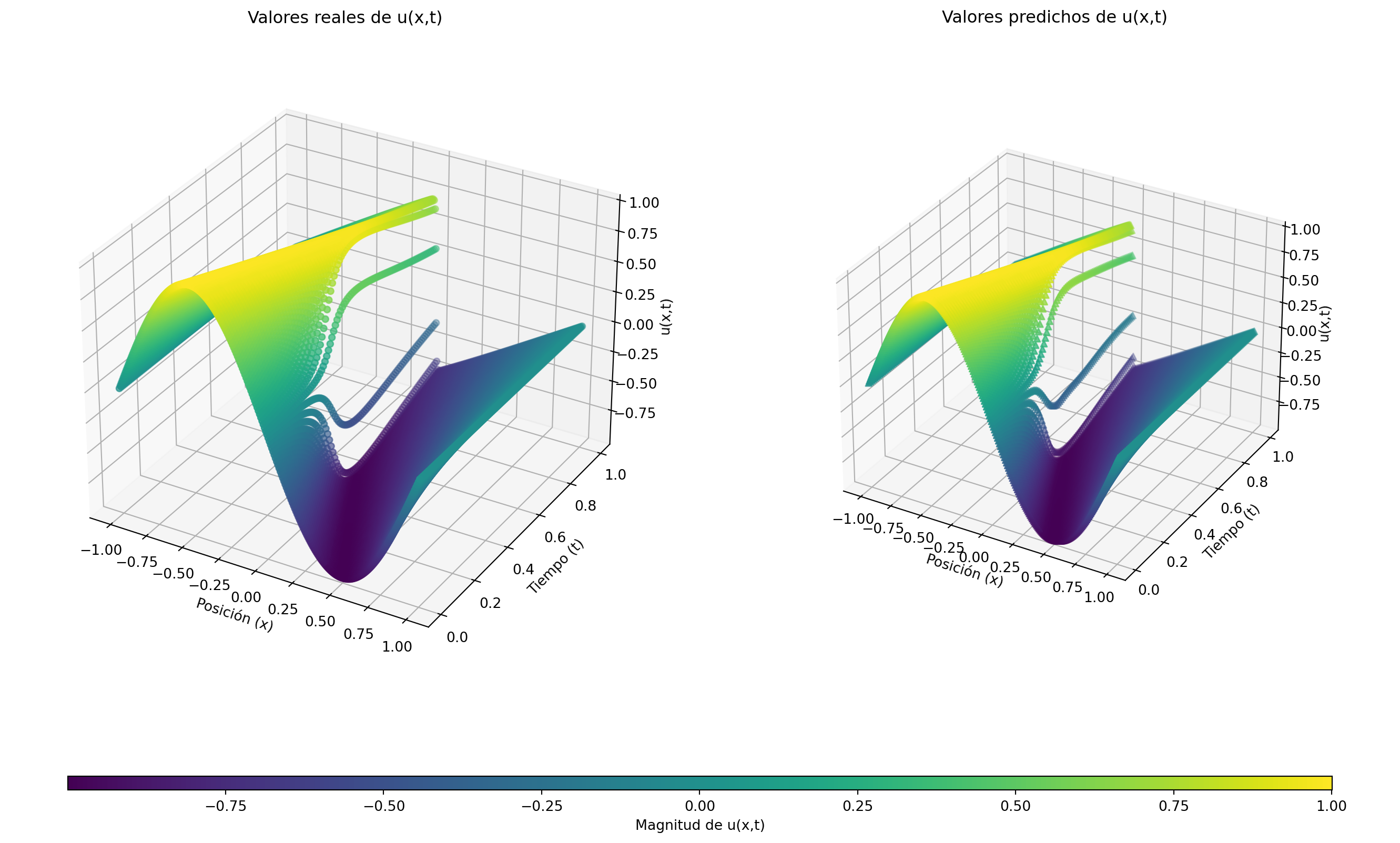
Figura 7.2: Comparación entre solución real y predicción de la red neuronal para la ecuación de Burger 1D. Debido a su naturaleza unidimensional, es posible plasmar en un eje al tiempo (t) y representar a la función a lo largo de éste como una serie de fotos para un instante \(t\) dado.
Error relativo L2: 0.016544904890081934
7.4 Comparación con Redes Neuronales Tradicionales
Mientras que las redes neuronales tradicionales dependen exclusivamente de grandes volúmenes de datos etiquetados para su entrenamiento (George Em Karniadakis 2021), las PINNs integran el conocimiento físico como parte esencial de su arquitectura (Blechschmidt y Ernst 2021). Esta diferencia clave permite a las PINNs generar soluciones físicamente consistentes incluso con datos escasos, evitando el sobreajuste común en enfoques puramente basados en datos. Otra ventaja significativa de las PINNs es su naturaleza mesh-free, que contrasta con los métodos numéricos tradicionales como FEM (Finite Element Method) o FDM (Finite Difference Method) que requieren discretización espacial. Sin embargo, el entrenamiento de PINNs puede ser más desafiante debido a la necesidad de optimizar múltiples objetivos simultáneamente (ajuste a datos y cumplimiento de leyes físicas) (Blechschmidt y Ernst 2021; George Em Karniadakis 2021).
Blechschmidt, Jan, y Oliver G. Ernst. 2021. «Three ways to solve partial differential equations with neural networks—A review». GAMM-Mitteilungen 44 (2): e202100006. https://doi.org/10.1002/gamm.202100006.
George Em Karniadakis, Lu Lu, Ioannis G. Kevrekidis. 2021. «Physics-informed machine learning». Nature Reviews Physics 3 (6): 422-40. https://doi.org/10.1038/s42254-021-00314-5.
Goldfarb, Donald, Yi Ren, y Achraf Bahamou. 2016. «Practical Quasi-Newton Methods for Training Deep Neural Networks». arXiv preprint arXiv:1606.01205. https://arxiv.org/abs/1606.01205.
Kingma, Diederik P., y Jimmy Ba. 2014. «Adam: A Method for Stochastic Optimization». arXiv preprint arXiv:1412.6980. https://arxiv.org/abs/1412.6980.
Lu, Lu, Xuhui Meng, Zhiping Mao, y George Em Karniadakis. 2021. «DeepXDE: A deep learning library for solving differential equations». SIAM Review 63 (1): 208-28. https://doi.org/10.1137/19M1274067.