Esta sección presenta un análisis cualitativo de los resultados mediante la comparación directa entre las predicciones del modelo, las soluciones reportadas en el estudio de Alessio Borgi (2023), así como las obtenidas mediante el método de Crank Nicolson y la solución analítica. La visualización paralela permite evaluar:
Dominio espacial: Cuadrado unitario [0,1] × [0,1] con malla 26×26.
Escala de colores: Mapa térmico YlGnBu y viridis (consistente en sus respectivos gráficos).
14.1.1 Modelo contra resultados de Alessio Borgi (2023)
El siguiente código grafica las predicciones de la red neuronal DeepONet para la temperatura dadas las coordenadas espaciales en los distintos tiempos de interés, los ejes están adimencionalizados siguiendo las ecuaciones 9.2.
Código
import matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Dimport matplotlib.gridspec as gridspecimport pandas as pdimport numpy as np# Lista de tiempostimes = [0.0, 0.25, 0.5, 0.75, 1.0]# Cargar el dataframedf = pd.read_csv(r'data/model_DoN.csv') # Crear figura con subplots 3D en 1 fila y 5 columnasfig, axes = plt.subplots(nrows=1, ncols=len(times), figsize=(28, 7), subplot_kw={'projection': '3d'})plt.subplots_adjust(right=0.8)# Asumimos que el grid es regularnum_points =int(np.sqrt(df[df["time"] == times[0]].shape[0]))# Lista para almacenar los objetos surfacesurf_list = []# Reordenar para graficarfor i, (t_val, ax) inenumerate(zip(times, axes)):# Filtrar por tiempo actual df_t = df[df["time"] == t_val]# Obtener los valores de X, Y, Theta X_vals = df_t["X"].values.reshape((num_points, num_points)) Y_vals = df_t["Y"].values.reshape((num_points, num_points)) Z_vals = df_t["Theta"].values.reshape((num_points, num_points))# Dibujar la superficie surf = ax.plot_surface( Y_vals, X_vals, Z_vals, rstride=1, cstride=1, cmap="YlGnBu", edgecolor="none", antialiased=True ) surf_list.append(surf) ax.set_title(f"Time = {t_val:.2f}", pad=10) ax.set_xlabel("Y", labelpad=10) ax.set_ylabel("X", labelpad=10) ax.set_zlabel("T [θ]", labelpad=10, rotation=90) ax.set_box_aspect(None, zoom=0.75)# Añadir barra de color comúncbar = fig.colorbar(surf_list[-1], ax=axes, shrink=0.9, aspect=90, pad=0.1, orientation='horizontal')cbar.set_label('Temperatura [θ]')plt.show()
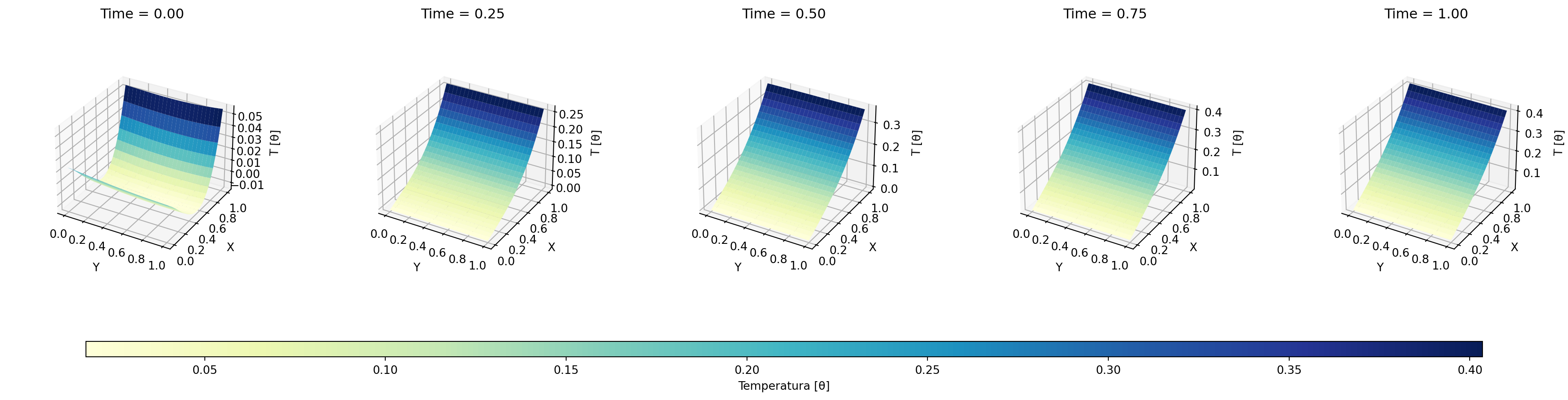
Figura 14.1: Predicciones de la red neuronal a distintos tiempos.
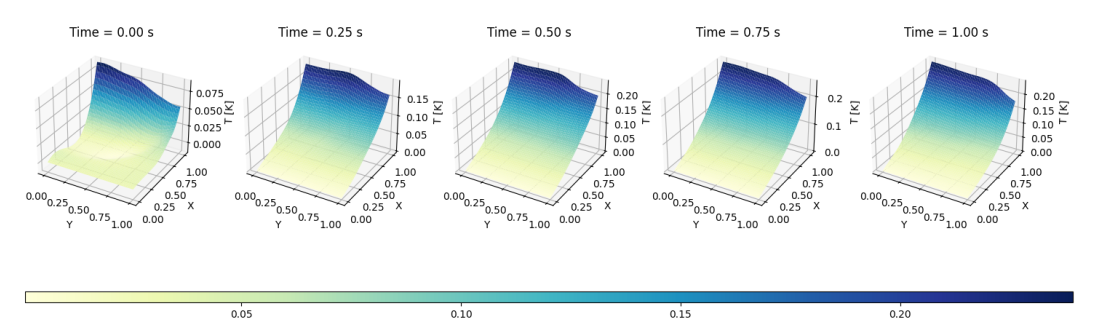
Figura 14.2: Resultados reportados por Alessio Borgi (2023) en el caso 2D.
La comparación visual entre las predicciones del modelo DeepONet Figura 14.1 y los resultados de , Figura 14.2 revela una notable similitud en la evolución temporal y espacial de la temperatura. Ambos modelos capturan la misma tendencia de calentamiento progresivo, con un gradiente térmico que se intensifica cerca de la frontera derecha (\(x=1\)), donde se aplica una condición de Neumann no homogénea. Sin embargo, se observa que en \(t=0\), el modelo DeepONet se aproxima con mayor fidelidad al plano \(XY=0\), lo que sugiere una mejor captura de la condición inicial en comparación con el trabajo de referencia.
14.1.2 Modelo contra método numérico
La siguiente gráfica utiliza los archivos csv obtenidos de los códigos 13.1 y 12.1 para motrar una comparativa entre los tiempos de interés, las predicciones del modelo se encuentran en la parte superior mientras que las del método numérico en la parte inferior.
Código
crank_nick_data = pd.read_csv(r'data/crank_nick.csv')model_don_data = pd.read_csv(r'data/model_DoN.csv')# Determinar los límites comunes para el colorbarmin_temp =min(model_don_data['Theta'].min(), crank_nick_data['Theta'].min())max_temp =max(model_don_data['Theta'].max(), crank_nick_data['Theta'].max())# Crear figura con subplots 3D en 2 filas y 5 columnasfig = plt.figure(figsize=(22, 12))axes = []# Crear los subplotsfor i inrange(2): # 2 filasfor j inrange(5): # 5 columnas axes.append(fig.add_subplot(2, 5, i*5+ j +1, projection='3d'))axes = np.array(axes).reshape(2, 5)# Añadir títulos generales para cada filafig.text(0.5, 0.92, "Predicciones modelo DON", ha='center', va='center', fontsize=14,fontweight='bold')fig.text(0.5, 0.58, "Predicciones método numérico", ha='center', va='center', fontsize=14, fontweight='bold')# Función para graficar un dataframe en una fila específicadef plot_dataframe(df, row, num_points, cmap="viridis"): surf_list = []for col, t_val inenumerate(times): ax = axes[row, col]# Filtrar por tiempo actual df_t = df[df["time"] == t_val]# Obtener los valores de X, Y, Theta X_vals = df_t["X"].values.reshape((num_points, num_points)) Y_vals = df_t["Y"].values.reshape((num_points, num_points)) Z_vals = df_t["Theta"].values.reshape((num_points, num_points))# Dibujar la superficie con límites comunes surf = ax.plot_surface( Y_vals, X_vals, Z_vals, rstride=1, cstride=1, cmap=cmap, edgecolor="none", antialiased=True, vmin=min_temp, vmax=max_temp ) surf_list.append(surf) ax.set_title(f"Time = {t_val:.2f}", pad=10) ax.set_xlabel("Y", labelpad=10) ax.set_ylabel("X", labelpad=10) ax.set_zlabel("T [θ]", labelpad=10, rotation=90) ax.set_box_aspect(None, zoom=0.75)return surf_list# Asumimos que el grid es regular para ambos dataframesnum_points =int(np.sqrt( model_don_data[model_don_data["time"] == times[0]].shape[0]))# Graficar el primer dataframe en la fila superiorsurf_model_don = plot_dataframe(model_don_data, 0, num_points)# Graficar el segundo dataframe en la fila inferiorsurf_crank_nick = plot_dataframe(crank_nick_data, 1, num_points)# Añadir barra de color común en la parte inferiorcbar = fig.colorbar(surf_crank_nick[-1], ax=axes.ravel().tolist(), use_gridspec=True, orientation='horizontal', pad=0.05, aspect=90, shrink=0.9)cbar.set_label('Temperatura [θ]', labelpad=10)plt.show()
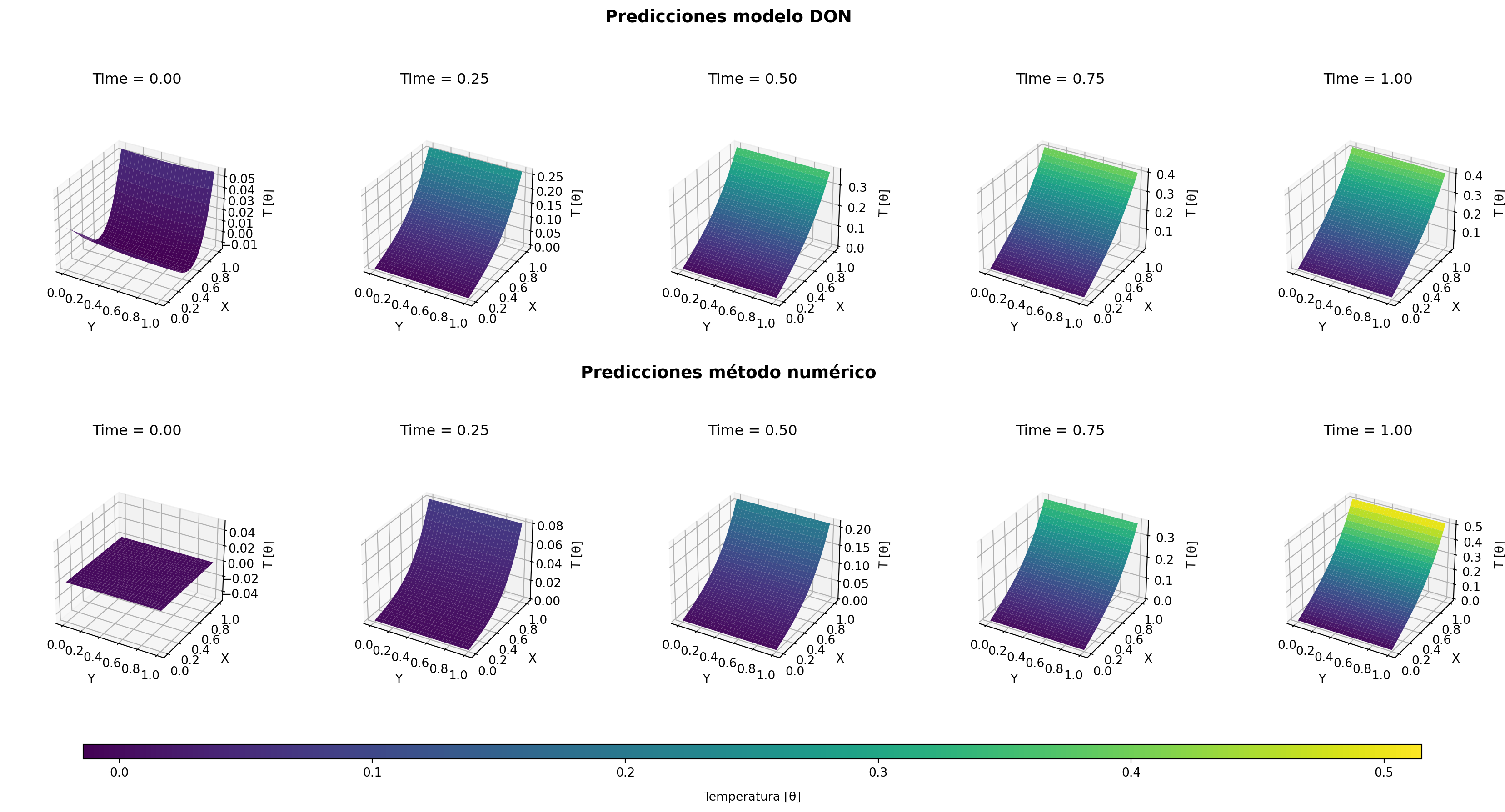
Figura 14.3: Contraste de las predicciones entre el modelo y el método de Crank Nicolson para cada tiempo. Se aprecia que ambas comparten forma y tendencia, sin embargo a medida que el tiempo se acerca a t=1 los resultados divergen.
Al contrastar las predicciones del modelo con las obtenidas mediante el método de Crank-Nicolson Figura 14.3, se confirma que ambas soluciones comparten la misma estructura general y comportamiento temporal. No obstante, a medida que el tiempo avanza hacia \(t=1\), se aprecia una ligera divergencia en la magnitud de la temperatura, especialmente en la región cercana a \(x=1\), donde el gradiente impuesto introduce mayor sensibilidad numérica.
14.1.3 Modelo contra solución analítica
La siguiente gráfica utiliza los archivos csv obtenidos de los códigos 13.1 y 9.1 para mostrar una comparativa entre los tiempos de interés, las predicciones del modelo se encuentran en la parte superior mientras que las de la solución analítica en la parte inferior.
Código
sol_ana_data = pd.read_csv(r'data/sol_analitica.csv')model_don_data = pd.read_csv(r'data/model_DoN.csv')# Determinar los límites comunes para el colorbarmin_temp =min(model_don_data['Theta'].min(), sol_ana_data['Theta'].min())max_temp =max(model_don_data['Theta'].max(), sol_ana_data['Theta'].max())# Crear figura con subplots 3D en 2 filas y 5 columnasfig = plt.figure(figsize=(22, 12))axes = []# Crear los subplotsfor i inrange(2): # 2 filasfor j inrange(5): # 5 columnas axes.append(fig.add_subplot(2, 5, i*5+ j +1, projection='3d'))axes = np.array(axes).reshape(2, 5)# Añadir títulos generales para cada filafig.text(0.5, 0.92, "Predicciones modelo DON", ha='center', va='center', fontsize=14,fontweight='bold')fig.text(0.5, 0.58, "Predicciones de la Sol. analítica", ha='center', va='center', fontsize=14, fontweight='bold')# Función para graficar un dataframe en una fila específicadef plot_dataframe(df, row, num_points, cmap="viridis"): surf_list = []for col, t_val inenumerate(times): ax = axes[row, col]# Filtrar por tiempo actual df_t = df[df["time"] == t_val]# Obtener los valores de X, Y, Theta X_vals = df_t["X"].values.reshape((num_points, num_points)) Y_vals = df_t["Y"].values.reshape((num_points, num_points)) Z_vals = df_t["Theta"].values.reshape((num_points, num_points))# Dibujar la superficie con límites comunes surf = ax.plot_surface( Y_vals, X_vals, Z_vals, rstride=1, cstride=1, cmap=cmap, edgecolor="none", antialiased=True, vmin=min_temp, vmax=max_temp ) surf_list.append(surf) ax.set_title(f"Time = {t_val:.2f}", pad=10) ax.set_xlabel("Y", labelpad=10) ax.set_ylabel("X", labelpad=10) ax.set_zlabel("T [θ]", labelpad=10, rotation=90) ax.set_box_aspect(None, zoom=0.75)return surf_list# Asumimos que el grid es regular para ambos dataframesnum_points =int(np.sqrt( model_don_data[model_don_data["time"] == times[0]].shape[0]))# Graficar el primer dataframe en la fila superiorsurf_model_don = plot_dataframe(model_don_data, 0, num_points)# Graficar el segundo dataframe en la fila inferiorsurf_crank_nick = plot_dataframe(sol_ana_data, 1, num_points)# Añadir barra de color común en la parte inferiorcbar = fig.colorbar(surf_crank_nick[-1], ax=axes.ravel().tolist(), use_gridspec=True, orientation='horizontal', pad=0.05, aspect=90, shrink=0.9)cbar.set_label('Temperatura [θ]', labelpad=10)plt.show()
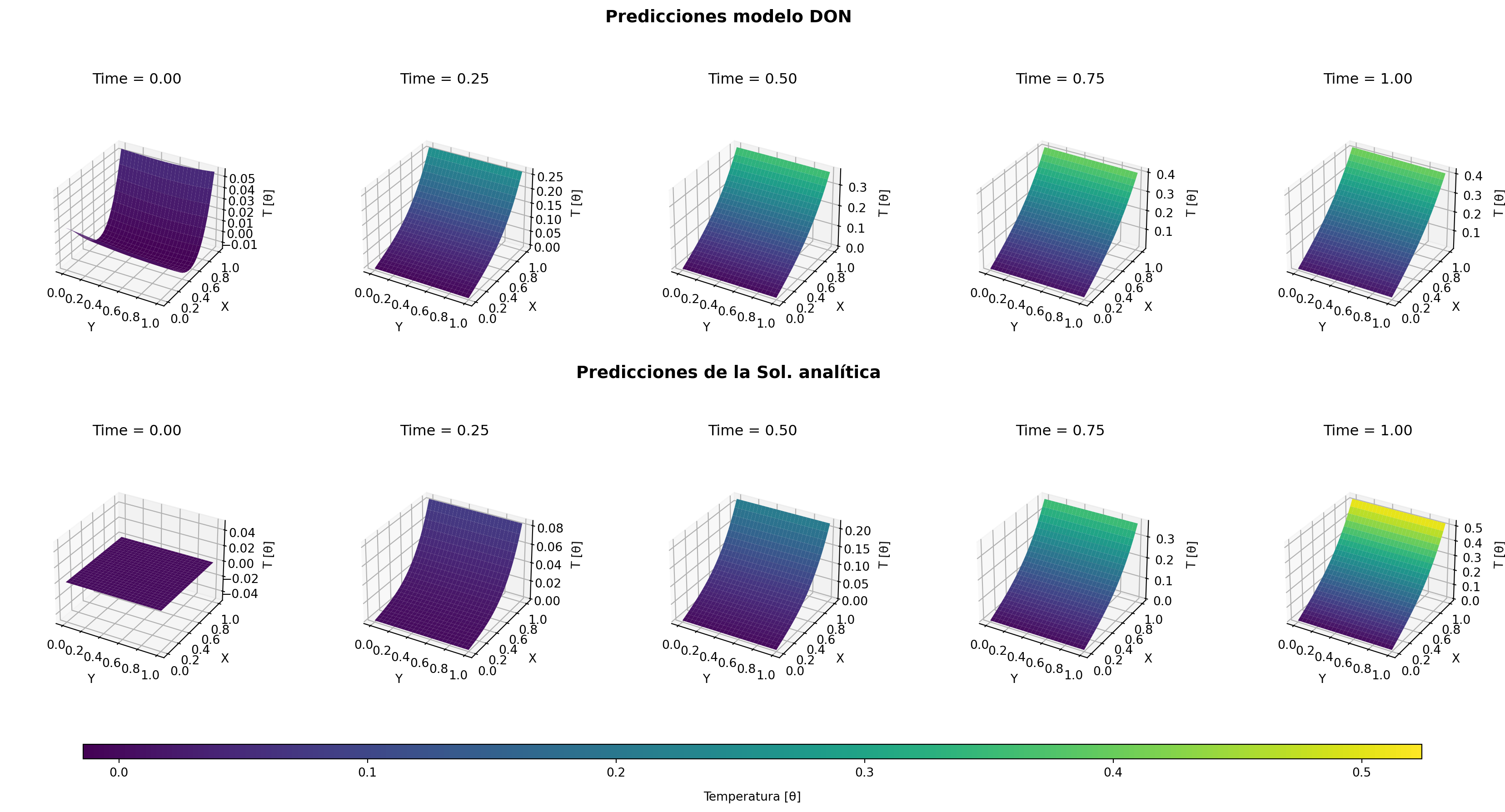
Figura 14.4: Contraste de las predicciones entre el modelo y la solución analítica para cada tiempo. Se aprecia que ambas comparten forma y tendencia, sin embargo a medida que el tiempo se acerca a t=1 los resultados divergen.
Finalmente, la comparación con la solución analítica Figura 14.4 refuerza la validez del modelo DeepONet. Aunque la forma general de la solución es consistentemente recuperada, se observa que las discrepancias aumentan levemente con el tiempo, lo cual es esperable dada la naturaleza truncada de la solución analítica y la aproximación inherente de la red neuronal.
14.2 Validaciones cuantitativas
14.2.1 Modelo contra el método de Crank-Nicolson
Para evaluar numéricamente la precisión del modelo DeepONet, se realizó una comparación sistemática con soluciones de referencia generadas mediante el método de Crank-Nicolson. Este enfoque proporciona una métrica objetiva de la exactitud del modelo, siendo complementado con una serie de gráficos que muestran el error absoluto para cada punto del dominio en los tiempos de interés.
Código
# Función para calcular erroresdef calculate_errors(true_data, pred_data, times): results = []for time in times:# Filtrar datos por tiempo true_subset = true_data[true_data['time'] == time] pred_subset = pred_data[pred_data['time'] == time]iflen(true_subset) ==0orlen(pred_subset) ==0:print(f"Advertencia: No hay datos para tiempo t={time}")continue# Verificar que las dimensiones coincidaniflen(true_subset) !=len(pred_subset):print(f"Advertencia:Num de puntos no coincide para t={time}") min_len =min(len(true_subset), len(pred_subset)) true_subset = true_subset.iloc[:min_len] pred_subset = pred_subset.iloc[:min_len]# Calcular errores para Theta theta_true = true_subset['Theta'].values theta_pred = pred_subset['Theta'].values absolute_error = np.abs(theta_true - theta_pred) l2_error = np.sqrt(np.sum((theta_true - theta_pred)**2)) results.append({'time': time,'mean_absolute_error': np.mean(absolute_error),'max_absolute_error': np.max(absolute_error),'l2_error': l2_error })return pd.DataFrame(results)# Calcular erroreserror_results = calculate_errors(crank_nick_data, model_don_data, times)# Guardar resultadoserror_results.to_csv("data/error_crank_nic.csv", index=False)
Tabla 14.1: Desviación del modelo DeepONet respecto a Crank-Nicolson.
Tiempo
MAE
MaxAE
Error L2
0.000
0.013
0.055
0.457
0.250
0.067
0.182
2.250
0.500
0.070
0.156
2.205
0.750
0.035
0.052
0.992
1.000
0.028
0.107
1.040
Las métricas de error calculadas —Error Absoluto Medio (MAE), Error Absoluto Máximo (MaxAE) y Error L2— confirman el buen desempeño del modelo DeepONet. En la comparación con el método de Crank-Nicolson Tabla 14.1, el MAE se mantuvo entre 0.013 y 0.07, con un valor máximo de 0.182 en el MaxAE. Estos valores reflejan una aproximación satisfactoria, aunque se observa que los errores tienden a aumentar en tiempos intermedios (\(t=0.25\) y \(t=0.5\)), posiblemente debido a la mayor complejidad dinámica en esas etapas.
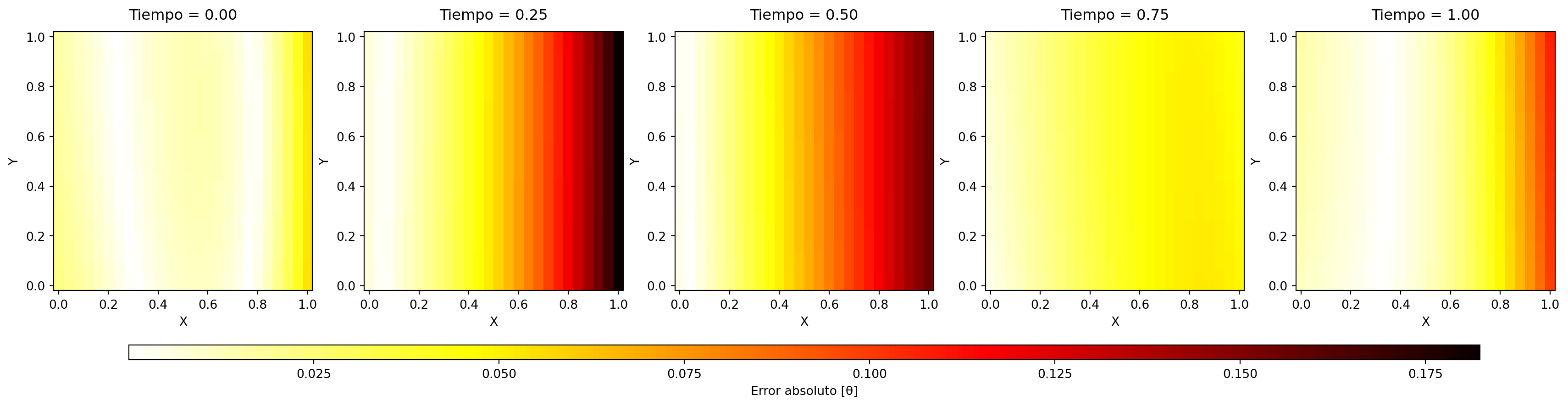
14.2.1.1 Gráficas de error absoluto
Código
# Calcular el error absoluto entre los dos dataframeserror_data = model_don_data.copy()error_data['error'] = np.abs( crank_nick_data['Theta'] - model_don_data['Theta'])# Crear figura con 3 filas y 2 columnasfig, axes = plt.subplots(nrows=1, ncols=5, figsize=(22, 8))axes = axes.ravel() # Convertir a array 1D para fácil acceso# Asumir que el grid es regularnum_points =int(np.sqrt( error_data[error_data["time"] == times[0]].shape[0] ))# Configuración común para los mapas de calorplot_kwargs = {'cmap': 'hot_r','shading': 'auto','vmin': error_data['error'].min(),'vmax': error_data['error'].max()}# Lista para guardar los gráficosabs_errors_pc = []# Crear los subplotsfor i, t_val inenumerate(times): ax = axes[i]# Filtrar por tiempo actual df_t = error_data[error_data["time"] == t_val]# Obtener valores y reshape X_vals = df_t["X"].values.reshape((num_points, num_points)) Y_vals = df_t["Y"].values.reshape((num_points, num_points)) error_vals = df_t["error"].values.reshape((num_points, num_points))# Crear mapa de calor pc = ax.pcolormesh(X_vals, Y_vals, error_vals, **plot_kwargs)# Configuración de ejes ax.set_title(f"Tiempo = {t_val:.2f}", pad=10) ax.set_xlabel("X") ax.set_ylabel("Y") ax.set_aspect('equal') abs_errors_pc.append(pc)cbar = fig.colorbar(abs_errors_pc[-1], ax=axes, use_gridspec=True, shrink=0.9, aspect=90, pad=0.1, orientation='horizontal')cbar.set_label('Error absoluto [θ]')# Mostrar el gráficoplt.show()
Figura 14.5: Errores absolutos entre el modelo y el método de Crank Nicolson para cada tiempo.
14.2.2 Modelo contra la solución analítica
De manera análoga a la sección anterior se realizó una comparativa contra la solución analítica (Sección 9.3). De este modo se tiene una visión más completa acerca del rendimiento del modelo.
Código
# Función para calcular erroresdef calculate_errors(true_data, pred_data, times): results = []for time in times:# Filtrar datos por tiempo true_subset = true_data[true_data['time'] == time] pred_subset = pred_data[pred_data['time'] == time]iflen(true_subset) ==0orlen(pred_subset) ==0:print(f"Advertencia: No hay datos para tiempo t={time}")continue# Verificar que las dimensiones coincidaniflen(true_subset) !=len(pred_subset):print(f"Advertencia:Num de puntos no coincide para t={time}") min_len =min(len(true_subset), len(pred_subset)) true_subset = true_subset.iloc[:min_len] pred_subset = pred_subset.iloc[:min_len]# Calcular errores para Theta theta_true = true_subset['Theta'].values theta_pred = pred_subset['Theta'].values absolute_error = np.abs(theta_true - theta_pred) l2_error = np.sqrt(np.sum((theta_true - theta_pred)**2)) results.append({'time': time,'mean_absolute_error': np.mean(absolute_error),'max_absolute_error': np.max(absolute_error),'l2_error': l2_error })return pd.DataFrame(results)# Calcular erroreserror_results = calculate_errors(sol_ana_data, model_don_data, times)# Guardar resultadoserror_results.to_csv("data/error_ana.csv", index=False)
Tabla 14.2: Error del modelo DeepONet respecto a la solución analítica.
Tiempo
MAE
MaxAE
Error L2
0.000
0.013
0.055
0.457
0.250
0.067
0.180
2.221
0.500
0.068
0.151
2.143
0.750
0.032
0.047
0.905
1.000
0.031
0.116
1.153
Al comparar con la solución analítica Tabla 14.2, los errores son consistentemente bajos, con un MAE máximo de 0.068 y un MaxAE de 0.18. La similitud entre ambas tablas sugiere que el método de Crank-Nicolson y la solución analítica están bien alineados, y que el modelo DeepONet se aproxima a ambos con un nivel de error comparable.
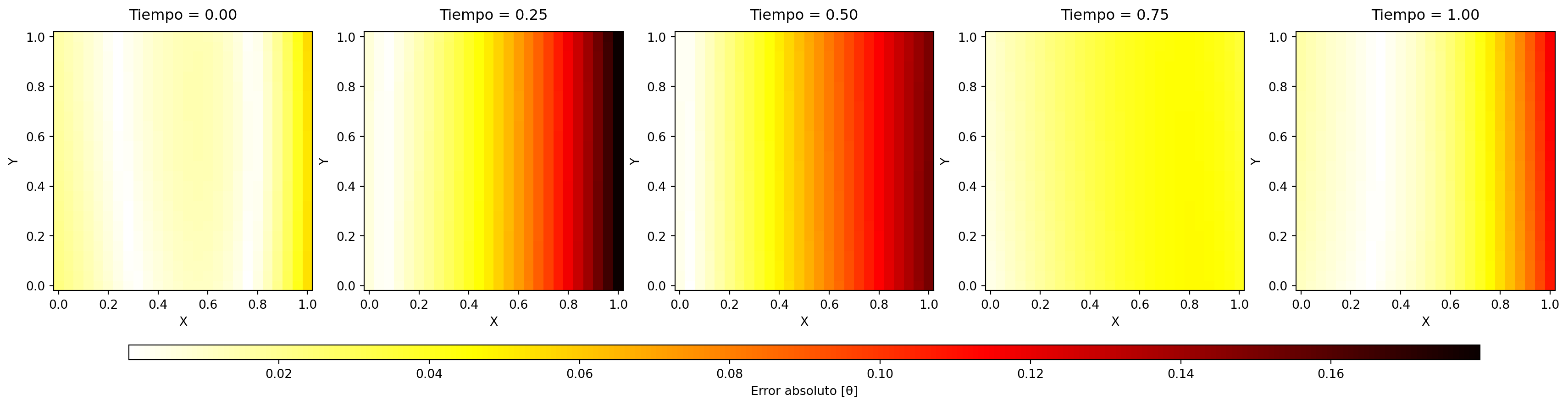
14.2.2.1 Gráficas de error absoluto
Código
# Calcular el error absoluto entre los dos dataframeserror_data = model_don_data.copy()error_data['error'] = np.abs( sol_ana_data['Theta'] - model_don_data['Theta'])# Crear figura con 3 filas y 2 columnasfig, axes = plt.subplots(nrows=1, ncols=5, figsize=(22, 8))axes = axes.ravel() # Convertir a array 1D para fácil acceso# Asumir que el grid es regularnum_points =int(np.sqrt( error_data[error_data["time"] == times[0]].shape[0] ))# Configuración común para los mapas de calorplot_kwargs = {'cmap': 'hot_r','shading': 'auto','vmin': error_data['error'].min(),'vmax': error_data['error'].max()}# Lista para guardar los gráficosabs_errors_pc = []# Crear los subplotsfor i, t_val inenumerate(times): ax = axes[i]# Filtrar por tiempo actual df_t = error_data[error_data["time"] == t_val]# Obtener valores y reshape X_vals = df_t["X"].values.reshape((num_points, num_points)) Y_vals = df_t["Y"].values.reshape((num_points, num_points)) error_vals = df_t["error"].values.reshape((num_points, num_points))# Crear mapa de calor pc = ax.pcolormesh(X_vals, Y_vals, error_vals, **plot_kwargs)# Configuración de ejes ax.set_title(f"Tiempo = {t_val:.2f}", pad=10) ax.set_xlabel("X") ax.set_ylabel("Y") ax.set_aspect('equal') abs_errors_pc.append(pc)cbar = fig.colorbar(abs_errors_pc[-1], ax=axes, use_gridspec=True, shrink=0.9, aspect=90, pad=0.1, orientation='horizontal')cbar.set_label('Error absoluto [θ]')# Mostrar el gráficoplt.show()
Figura 14.6: Errores absolutos entre el modelo y la solución analítica para cada tiempo.
Los mapas de error absoluto Figura 14.5 y Figura 14.6 permiten localizar espacialmente las discrepancias. Se observa que los mayores errores se concentran en la región de \(x=1\), donde la condición de Neumann no homogénea introduce mayores exigencias en la aproximación. Esta distribución del error es coherente con el comportamiento reportado en la literatura para problemas con condiciones de frontera variables en el tiempo.